

Книжная серия Тотального диктанта пополнилась еще одним экземпляром!

Научно-популярная книга "100 текстов о русском языке" расскажет о прошлом языка, его настоящем и будущем, об актуальных процессах в современной русской письменности, о вопросах цифрового этикета и деловой переписки, а также о взаимодействии языка и технологий и о тех изменениях, которые произошли или только произойдут в языковой системе.
Делимся с вами главой из книги "100 текстов о русском языке".
Автор: Станислав Ашманов
Как машины понимают наш язык
Что такое искусственный интеллект? У этого довольно размытого понятия есть много определений: от голливудских представлений о думающих машинах, которые превзойдут нас и захватят мир, до более прикладных формулировок. Мы с вами, как практики, будем использовать определение, которое более приближено к реальности:
«Искусственный интеллект — это инженерно-математическая дисциплина, занимающаяся созданием программ и устройств, имитирующих когнитивные (интеллектуальные) функции человека, включающие в том числе анализ данных и принятие решений».
Это определение не задается вопросом, как происходит принятие решений: если машина решает какую-то задачу, которую раньше решал только человек, то мы можем назвать ее искусственным интеллектом. И нам совершенно не принципиально, как она это делает с точки зрения технической реализации, будь то нейронные сети, работа со словарями или, например, какие-либо действия с регулярными выражениями.
Как мы можем научить машину принимать решения самостоятельно? Во-первых, здесь следует сказать о машинном обучении. В рамках этого метода работы с искусственным интеллектом мы говорим: «Давайте наберем побольше примеров того, как человек принимает какие-либо решения, и заставим машину самостоятельно выявить закономерности в этих данных». Например, возьмем сто тысяч текстов по двум категориям (позитивные и негативные отзывы о какой-либо компании), переведем их в машинно-читаемый формат, а далее отпустим компьютер в свободное плавание: пусть алгоритм сам подберет правильную стратегию классификации этих данных по двум «кучкам». Таким образом через некоторое время машина научится отличать одни отзывы от других, а нам для этого даже не придется сопоставлять словари, списки и придумывать эвристические правила классификации.
Во-вторых, нельзя не упомянуть экспертные системы. Возьмем на этот раз не тексты, а людей, например врачей, и пообщаемся с ними, а после внесем их знания в базу данных или экспертную систему принятия решений, на которые сможет опираться машина.
Задачи, которые предлагается решать искусственному интеллекту, многообразны: это и компьютерное зрение, и обработка речи, и анализ табличных данных, и еще многое и многое другое. Мы же с вами подробнее остановимся на анализе текстов.
Возможно, вы даже и не подозревали, что каждый день сталкиваетесь с узкоспециализированным текстовым искусственным интеллектом: именно такими словами можно определить известные поисковики («Яндекс», Google и др.) Существуют поисковые системы, которые ищут информацию не во всем открытом интернете, а, например, в определенной коллекции документов, и различные чат-боты («Алиса», «Маруся», «Марвин» и пр.). Так, наша компания разработала для Минздрава чат-бот «Зожик», который рассказывает о коронавирусе. Он берет проверенную информацию из верифицированных источников и сообщает человеку о симптомах болезни и о том, что следует делать, если он заболел.
Есть примеры и других задач — например, проверка правописания. Спелл-чекер — это тоже искусственный интеллект, который решает когнитивную задачу — задачу проверки текстов. И если раньше ее мог решать только профессиональный переводчик, лингвист или редактор, то теперь это автоматически может делать и текстовый редактор. Впрочем, пока у него не всегда получается справляться с этим так же хорошо, как это выходит у специалиста, но все же мы смогли в значительной степени автоматизировать одну из когнитивных функций человека.
А что с обработкой текстов? Базовая задача — это их классификация. Допустим, у нас есть миллион документов, причем их длина может быть различной: от поискового запроса пользователя до контрактов или жалоб граждан. Задача классификации состоит в том, чтобы «раскидать» большой массив документов по заранее определенным категориям (а в случае с чат-ботами — по намерениям пользователя) с учетом того, что одно и то же намерение («я хочу вызвать такси») может быть выражено бесконечным количеством способов («найди машину», «закажи»…).
Другая задача — извлечение фактов. Представьте переписку между компанией и заказчиком, из которой необходимо извлечь информацию о недовольстве последнего (а еще лучше — о том, чем именно он недоволен), после чего обратиться к контракту и определить, действительно ли были нарушены какие-то условия. Извлечение фактов может заключаться и в том, чтобы из неструктурированного массива документов выделять нужное, при этом преобразовывая этот массив в удобный формат, например табличный, с которым проще работать. Есть задача извлечения именованных сущностей: когда вы говорите: «Хочу заказать пиццу на улицу Паустовского, дом 12», — то «улица Паустовского, дом 12» в данном случае и будет такой сущностью, именуемой «адресом».
Другой кластер задач — задачи генерации текстов. Например, у нас есть карточки интернет-магазина и мы хотим по спискам параметров какого-либо товара сгенерировать связное и привлекательное для потенциального покупателя описание. Или, скажем, нужно сгенерировать ответ чат-бота на запрос пользователя «Покажи прогноз погоды на неделю». Разумеется, после того как чат-бот «сходил» в некоторую информационную систему и получил необходимые данные, он должен предоставить человеку не просто перечень чисел, а сформулированный, «гладкий» ответ на естественном языке.
Наконец, есть задача преобразования текстов. Самый простой пример — проставить ударения или буквы ё в словах, чтобы при синтезировании речи текст корректно читался машиной.
Везде мы работаем с текстовыми строками, которые нужно анализировать: это называется Natural Language Processing — обработка естественного языка. Эта обширная область иногда называется компьютерной лингвистикой.
Довольно много задач расположено на стыке с компьютерным зрением (например, генерация реалистичных трехмерных аватаров, которые правильно двигают губами, произнося заданный текст) и обработкой речи (ее распознавание или синтез).
Сейчас, когда мы примерно обозначили, какой круг задач, связанных с текстом, может стоять перед машиной, поговорим о том, как текст представляется в компьютере. Все изображения, видео или тексты отражаются в нем в численном виде, и, чтобы компьютер мог обработать что-либо, это нужно оцифро вать. Например, бумажные документы сканируют — и они появляются в виде картинок, но этого недостаточно, чтобы машина могла работать с текстом: предварительно картинки нужно распознать и перевести в текст.
У текстов всегда есть кодировка: каждой букве присваивается число — ее числовой код. Кроме того, мы можем присваивать разные числа словам, то есть работать не на уровне букв, а на уровне слов. Работать со строками в любом языке программирования довольно просто: всегда есть базовый тип данных — строка, и поэтому тексты легко подгружать, обрабатывать и использовать впоследствии (см. рисунок).
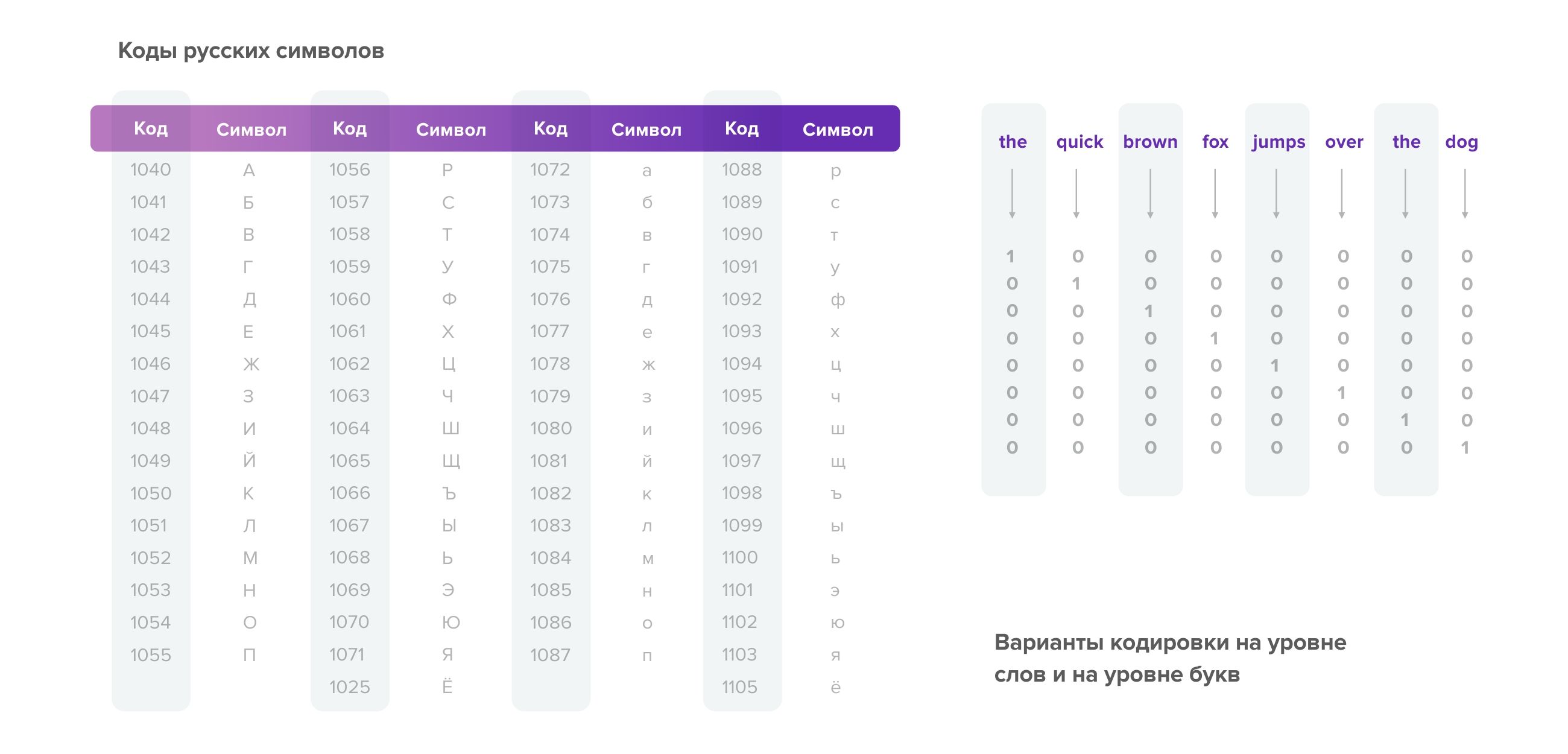
А что происходит с текстом при его обработке? Возьмем предложение-панграмму «Съешь еще этих мягких французских булок да выпей чаю». Во-первых, когда мы работаем с большими документами, надо всегда разбивать текст на предложения. Эта задача может быть нетривиальной, потому что концом предложения может быть точка, а может быть и какой-то другой символ, точки могут использоваться в сокращениях (например, «и т. д.», «др.», «ул.»).
Далее идет стадия разбивки текста на слова или, как еще говорят, на токены1, потому что кроме слов в предложении могут быть, например, знаки препинания. За ней следует стадия очистки от «мусорных», или, как их еще называют, «стоп-слов». В каждой конкретной задаче может быть свой собственный список таких выражений, потому что где-то можно выкинуть частицу не, а где-то ее исключение может придать высказыванию противоположный смысл. Выше вы видите пример того, как из предыдущего предложения были убраны незначимые слова.
- Разбивка на слова (токены)
['Съешь', 'же', 'еще', 'этих', 'мягких', 'французских', 'булок', 'да', 'выпей', 'чаю', '.']
- Чистка от мусорных слов (стоп-слова)
['Съешь', 'мягких', 'французских', 'булок', 'выпей', 'чаю', '.']
- Нормализация
'С вас 500 руб. 75 коп.' → 'С вас пятьсот рублей семьдесят пять копеек.'
Есть еще одна стадия нормализации: предположим, текст представлен в виде, который не совсем удобен для последующей обработки. Мы перевели численное представление в словесное, сохранив правильную падежную форму для каждого из слов. Этап нормализации крайне важен для синтеза речи, когда мы хотим, чтобы машина грамотно и корректно озвучила полученный текст.
- Лемматизация
'лучший' → 'хороший'
- Стеммизация
'коровка' → 'коров'
На стадии лемматизации мы приводим слово к лемме2, а при стеммизации «обрезаем» его до основы, чтобы не зависеть от падежей там, где они не важны. Существует стадия морфологического разбора, когда мы, например, «переводим» слово из винительного падежа в именительный, а на стадии синтаксического разбора строим синтаксическое дерево для данного предложения (что и чему подчиняется) и устанавливаем связи в предложении.
Не могу не сказать о технологии векторизации, когда для дальнейшей работы тексты переносятся в некоторое математическое многомерное пространство. Это позволяет очень грамотно «считывать» информацию о возможном значении слова, основываясь на совместной встречаемости слов. Идея, которая лежит в основе этой технологии, такова: давайте считать, что если слова встречаются в похожем контексте (если их «соседи» похожи), то и сами слова похожи. Можно сказать, что это приложение к анализу текстов знаменитого высказывания «Скажи мне, кто твой друг, и я скажу, кто ты!». Рассмотрим три предложения:
- Когда я вырасту, я стану врачом.
- Когда я вырасту, я стану строителем.
- Когда я вырасту, я стану шпателем.
Слова врач и строитель, вероятно, чем-то похожи, а вот слова шпатель в таком контексте не может быть. Отсюда и возникла технология, которая сперва называлась Word to Vec: основываясь на большом массиве текстов, мы подсчитываем совместные встречаемости слов (с чем рядом встречается слово врач, с чем рядом встречается слово стану, с чем рядом встречается слово когда) и после этого, опираясь на информацию о таких «соседях», можем что-то говорить и о самих словах. Сейчас очень популярна технология векторизации с помощью нейросетей, которые называются трансформерами: так, нейросеть BERT присваивает каждому слову вектор, а мы можем работать с этими векторами в математическом плане — складывать или сравнивать их по близости.
Если вы заинтересовались векторизацией, советую зайти на страницу «Семантического калькулятора» и провести классический эксперимент: взять слово король, вычесть из него слово мужчина и прибавить слово женщина (должно получиться слово королева). По сути, перед нами математическое выражение, только вместо цифр и чисел выступают слова естественного языка. Правда, иногда такая математика выдает очень смешные результаты, оценить всю абсурдность которых смогут те, кто владеет английским языком, но на практике векторизация очень полезна: с ее помощью мы можем понимать, что, хотя слово в тексте написано правильно, в данном конкретном предложении, вероятно, произошла какая-то ошибка и вместо одного слова подставилось другое. Опираясь на контекст, мы понимаем, что это слово из него выбивается: Я надел надувной спасательный круг vs Я надел надувной спасательный друг.
На этапе обработки мы подсчитываем частотность слов: если у нас большой корпус на сто гигабайт текстов, мы можем посчитать, как часто встречается то или иное слово в этих документах. Это может быть полезно для того, чтобы составить список стоп-слов или, наоборот, слов, которые несут позитивную окраску.
Для всего этого часто используются системы разметки текстов — такие инструменты или веб-сервисы, в которых разметчик (филолог или лингвист) может присвоить документам категории или выделить в них какие-то сущности. Это очень важно, если мы работаем с системами машинного обучения, потому что нейронная сеть обучается на больших массивах документов.
Какие существуют алгоритмы и библиотеки для работы с естественным языком? Популярная библиотека NLTK работает в том числе и с русским языком и аккумулирует и токенизацию, и лемматизацию, и другие этапы, о которых было сказано выше. Есть похожие библиотеки spaCy и pymorphy2, которые позволяют работать с падежами. Для построения нейронных сетей можно использовать нашу библиотеку Puzzle, а проект SOVA — это наша открытая платформа для создания чат-ботов.
Тема обработки естественного языка не только очень интересна, но и безумно востребована, хотя на рынке объективно не хватает специалистов. Если вам это интересно, изучайте искусственный интеллект, погружайтесь в него и становитесь разработчиком Natural Language Processing, потому что компьютерные лингвисты сейчас по-настоящему нужны.
токен1 — последовательность символов в лексическом анализе в информатике, соответствующая лексеме.
лемма2 — словарная форма слова

